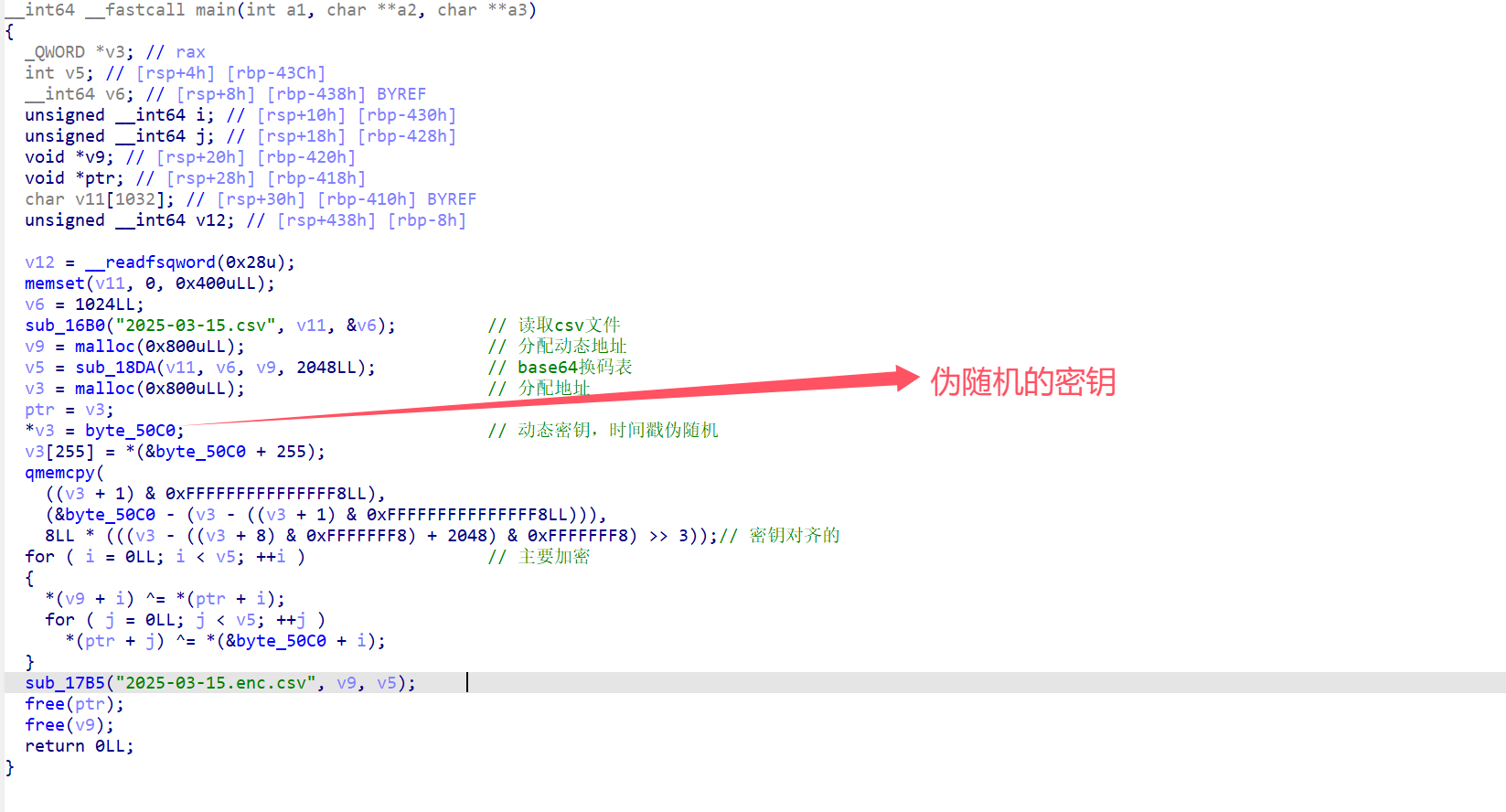
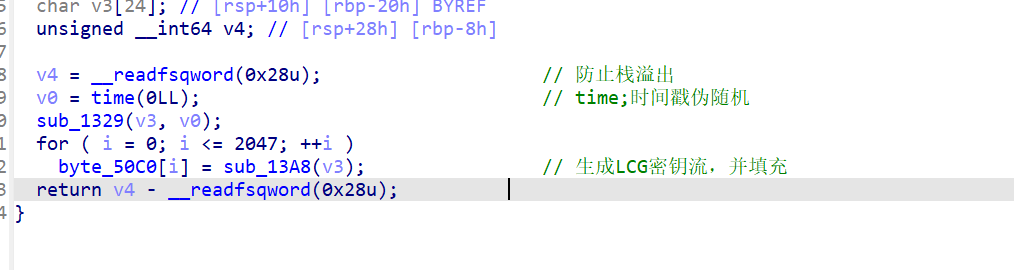
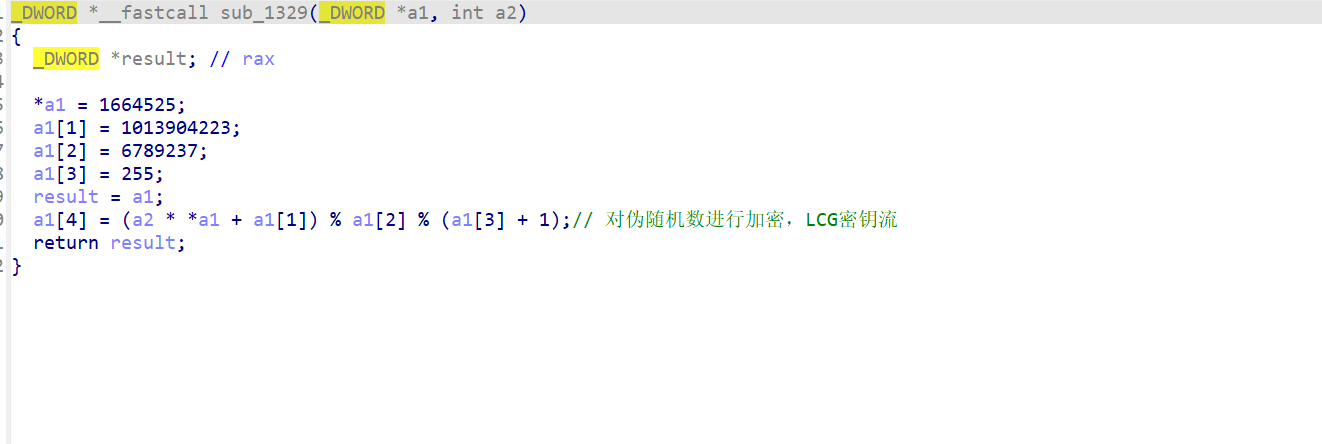
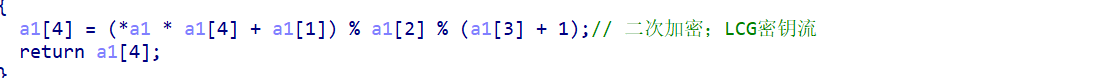encode_table = {standard_base64_chars[i]: custom_base64_chars[i] for i inrange(len(standard_base64_chars))} decode_table = {custom_base64_chars[i]: standard_base64_chars[i] for i inrange(len(custom_base64_chars))}
defcustom_base64_encode(data): standard_encoded = base64.b64encode(data) custom_encoded = bytearray(standard_encoded) for i inrange(len(custom_encoded)): custom_encoded[i] = encode_table.get(chr(custom_encoded[i]), chr(custom_encoded[i])).encode('utf-8')[0] returnbytes(custom_encoded)
defcustom_base64_decode(encoded_data): standard_encoded = bytearray(encoded_data) for i inrange(len(standard_encoded)): standard_encoded[i] = decode_table.get(chr(standard_encoded[i]), chr(standard_encoded[i])).encode('utf-8')[0] decoded_data = base64.b64decode(bytes(standard_encoded)) return decoded_data